Character Encoding and Representation #
This section explains the encoding and representation of characters using Unicode. It also describes the multiple methods used in combination to handle characters that cannot be represented by Unicode.
Character Encoding with Unicode #
The number of CJK Unified Ideographs differs depending on the Unicode version.
The HDIC project started in 2014, and initially, the baseline was Unicode 8.0.0 (from 2015). At that time, the number of usable Hanzi (Chinese characters) was 80,358, comprising CJK Unified Ideographs and CJK Unified Ideographs Extensions A through E.
Extensions have continued since then, with the total number of characters now exceeding 90,000. However, even after characters are included in Unicode, it seems to take time before they can actually be displayed on screens or used in print.
The HDIC project utilizes characters up to CJK Unified Ideographs Extension E as much as possible. For characters in Extension F and beyond, the project currently limits its practice to noting them in remarks columns or similar fields.
Representation of Characters Outside of Unicode #
“Characters outside of Unicode” refers to Hanzi (Chinese characters) that are not included in the Unicode standard.
These characters are represented using the following three methods:
- IDS Method
- Entity Reference Method
- Beta Method (β Method)
The IDS Method is used when a character can be represented by a combination of its constituent components, described using an IDS (Ideographic Description Sequence). The IDS data used and referenced in this project is primarily that constructed and made publicly available by Morioka Tomohiko in the CHISE IDS Search.
An IDS is indicated by IDCs (Ideographic Description Characters). The twelve IDCs are: ⿰, ⿱, ⿲, ⿳, ⿴, ⿵, ⿶, ⿷, ⿸, ⿹, ⿺, and ⿻.
Examples:
- Example of the IDS Method: ⿰亻胃 (representing a character with the ‘亻’ radical on the left and ‘胃’ on the right), ⿰亻⿱𡈼儿 (a variant of ‘凭’, an example using multiple IDCs).
If representation by the IDS Method is difficult, one of the following methods is used.
The Entity Reference Method involves describing characters using notations based on the entity reference systems of CHISE and GlyphWiki.
Examples:
- CHISE Entity Reference Method: ⿺辶&CDP-8C66; (a variant of ‘延’, where &CDP-8C66; represents the bottom-right component of ‘𠂢’, a glyph similar to 𧘇).
- GlyphWiki Entity Reference Method: koseki-007510 (representing a glyph with ‘ヽ’ at the top-right of ‘𠇾’).
The Beta Method (β Method) involves describing characters by combining a graphically similar character with Greek letters such as β (beta), γ (gamma), etc. This Beta Method was proposed by Toyoshima Masayuki.
Example:
- Example of the Beta Method: 正β (representing a glyph with two horizontal ‘ヽ’ strokes inside the ‘匸’ radical of ‘正’).
Characters that cannot be represented by any of the above methods, or characters that are illegible in the original manuscript (due to damage such as wormholes, etc.), are represented by ‘■’ (a black square). For more details on illegible characters, please refer to the section “Wormholes and Illegible Characters.”
Utilizing GlyphWiki #
To display glyphs in a Mincho typeface that closely approximate those in the manuscript, GlyphWiki (developed by Uechi Kōichi) can be utilized. By using GlyphWiki, it is possible to display such approximate Mincho-style glyphs.
The creation of glyph forms for the Headwords of the Myōgishō using GlyphWiki is currently in progress and not yet complete, but it is mentioned here for reference.
By associating GlyphWiki glyph numbers with the kazama_location_id found in the krm_headword_chars file, the Headwords of the Ruiju Myōgishō can be represented in a Mincho typeface.
The GlyphWiki glyph number is expressed by taking a prefix—formed by combining the abbreviation for this project (HDIC) with the abbreviation for the Kanchi-in manuscript of the Ruiju Myōgishō (KRM), resulting in hdic_hkrm-—and appending the numerical part of the kazama_location_id (from krm_headword_chars) after removing its ‘K’ prefix.
For example, for a Headword within an Entry (e.g., with an entry_id like F01234), if its corresponding kazama_location_id in the krm_headword_chars file is K01075140, then its GlyphWiki glyph number will be hdic_hkrm-01075140.
This will be demonstrated next using Markdown notation.
Example:
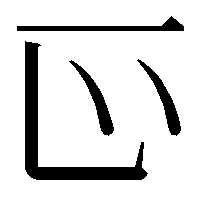
When described in Markdown as shown above, it will be displayed as follows:
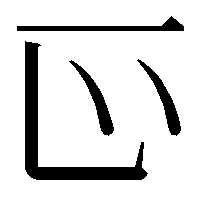
This character size is large; if you wish to use a smaller size, use the following notation:

When described in Markdown as shown above, it will be displayed as follows:

Note that the filename hdic_hkrm-01075140.png is derived from the numerical part of the kazama_location_id K01075140 found in the krm_headword_chars file.
To display it with a specified size, you can write it as follows:
{{< figure src=“https://glyphwiki.org/glyph/hdic_hkrm-01075140.png" title=”" class=“center” width=“24” height=“24” >}}
{kind=link}