文字の符号化と表現 #
ここでは、Unicodeを利用した文字の符号化と表現を解説する。 Unicode によって表現できない文字の扱いは複数の方式を併用しているので、その点も解説する。
Unicodeによる文字の符号化 #
UnicodeのバージョンによりCJK統合漢字の数は異なる。 HDICプロジェクトとしては2014年にスタートしており、当初、基本に据えたのは2015年のUnicode 8.0.0であり、使用できる漢字の数は、 CJK統合漢字とCJK統合漢字拡張A-Eの80,358字である。 その後も拡張が続いており、90,000字を超えるところまで きている。ただ、Unicodeに収録されても、実際に画面に表示したり、 印刷したりして使えるようになるのは時間がかかるようである。CJK統合漢字 拡張Eまでを可能な限り利用し、拡張F以降は、データベース作成者が備考欄などに注記するにとどめている。
Unicode外の文字の表現 #
Unicode外の文字とは、Unicodeに収録されていない漢字のことである。 Unicode外の文字は、次の三つの方法で表現する。
- IDS方式
- 実体参照方式
- β方式
IDS方式は 漢字の部品の組み合わせで表現可能な場合に、IDS(漢字構成記述文字列、Ideographic Description Sequence)で記述する方式である。 IDSのデータは守岡知彦氏がCHISE IDS検索で構築・公開しているものを利用・参照している。
IDSはIDC(漢字構成記述文字、Ideographic Description Character)により示す。 IDCは⿰ ⿱ ⿲ ⿳ ⿴ ⿵ ⿶ ⿷ ⿸ ⿹ ⿺ ⿻の12字である。
例
- IDS方式の例:⿰亻胃(人偏に胃を書く字形)、⿰亻⿱𡈼儿(凭の異体字、複数のIDCを使用した例)
IDS方式で表現が困難な場合は、次のいずれかの方法を用いる。
実体参照方式は CHISEおよびGlyphWikiの実体参照方式に基づいた表記で記述する方式である。
例
- CHISEの実体参照方式:⿺辶&CDP-8C66; (延の異体字、&CDP-8C66;は𠂢の右下部分の字形、𧘇に近似した字形)
- GlyphWikiの実体参照方式:koseki-007510 (𠇾の右上にヽの字形)
β方式は 近い字形とβ、γ等とを組み合せて記述する方式である。
例
- β方式の例:正β (匸の中にヽが横に二つの字形)
上記のいずれの方法でも表現できない文字や、原典で判読不能な文字(虫損等)は、「■」(黒い四角)で記述する。 原典で判読不能な文字の詳細は「虫損・判読不能」のセクションを参照。
GlyphWikiの利用 #
近似した明朝体の字形を表示するために GlyphWiki(上地宏一氏)を利用すれば、 近似した明朝体の字形を表示することができる。
GlyphWikiを利用した名義抄の掲出字の字形の作成は、作業中であり、 完成していないが、参考に記しておく。
GlyphWikiのグリフ番号を、krm_headword_charsのkazama_location_idに対応させることで、
類聚名義抄の掲出字を明朝体字形で表現する。
GlyphWikiのグリフ番号は、このプロジェクトの略称であるHDICと
観智院本名義抄の略称(KRM)を組み合わせたプリフィックス
hdic_hkrm-を冠し、krm_headword_charsのkazama_location_idのプリフィックスKを除いた数値部分を組み合わせて表現する。
たとえば、掲出項目ID(entry_id)がF01852の掲出字について、対応する krm_headword_chars の kazama_location_id が K01075140 である場合、そのGlyphWikiのグリフ番号は hdic_hkrm-01075140 となる。
次にはMarkdownの記法で示す。
例
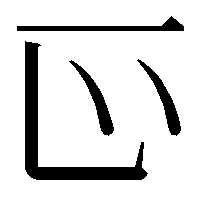
とすると、次のように表示される。
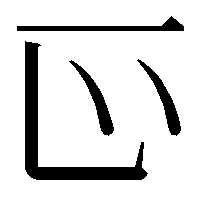
これでは文字サイズが大きいので、小さいサイズを使う場合には

とすれば、次のように表示される。

なお、ファイル名hdic_hkrm-01075140.pngは、krm_headword_charsのkazama_location_idの
K01075140の数値をとったものである。
サイズを指定して表示するには次のように記載すればよい。
{{< figure src=“https://glyphwiki.org/glyph/hdic_hkrm-01075140.png" title=”" class=“center” width=“24” height=“24” >}}
{kind=link}